

Photo by Jake Nackos on Unsplash
A common pattern when using microservice is the need for a microservice to update its own database and to send an event to propagate the information to other services, typically through a message broker as Kafka.
It is important to maintain data consistency when performing those two operations. Simply put, those operations are done atomically.
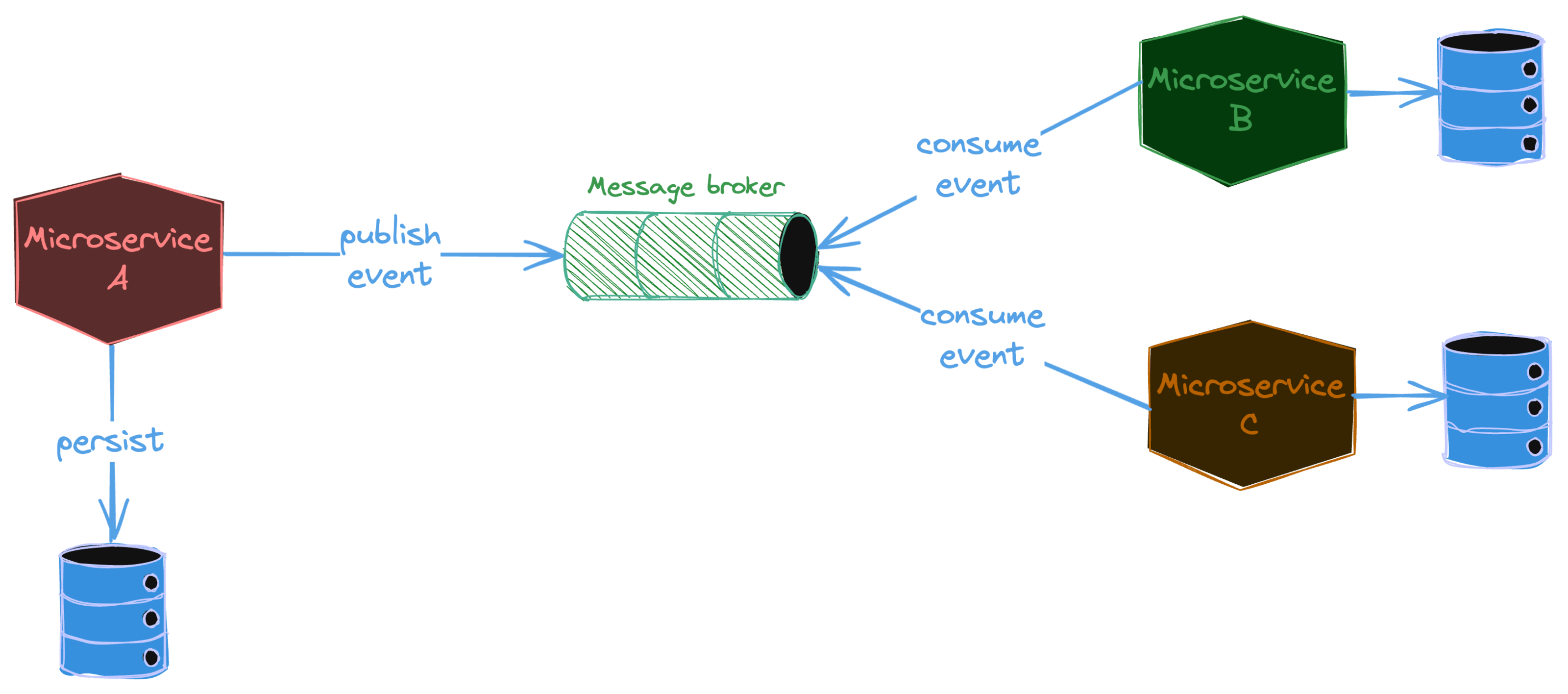
What could go wrong if operations run independently?
Although message broker like Kafka is considered durable, downtime will still happen in reality. Note that the communication between message broker and service A is synchronous, so they are coupled together. Service A knows if its message was delivered to the message broker once it receives the acknowledgement. If the message broker is unavailable, then event is not sent to consumer services. We have a situation where data changes were committed in service A's local database, but other services are unaware of them.
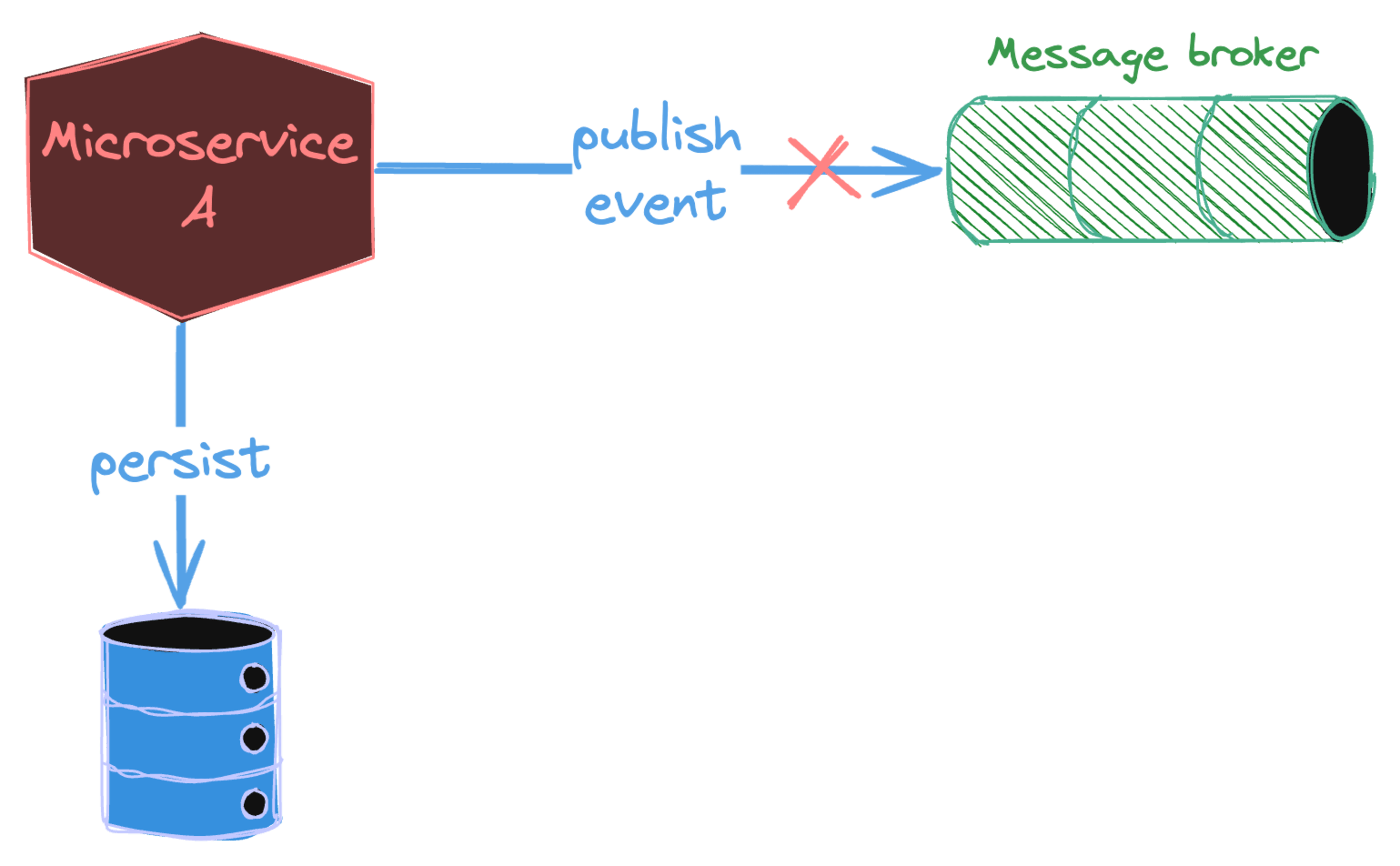
A simple method is to implement retry, our Kafka producers (let's assume we use Kafka from now on) retry the delivery of the failed messages to the broker for retryable errors (e.g., not enough replicas exception). We can configure our producers to be idempotent, and Kafka will automatically deduplicate messages. If you are using frameworks like Spring with Spring Kafka, the retry mechanism is supported out of the box.
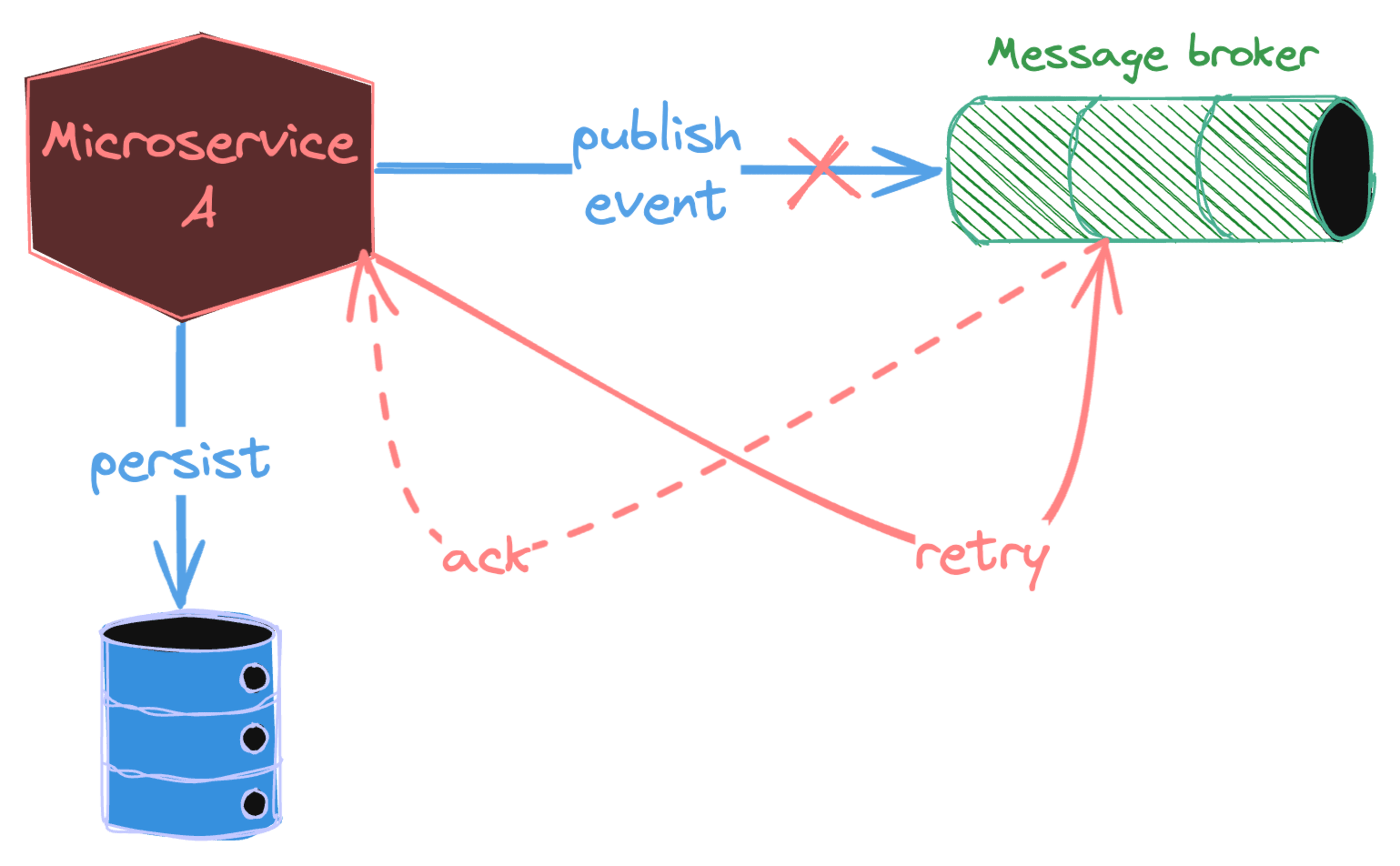
However, even retrying messages does not guarantee that consumer services will receive them. As messages are stored in application memory, if service A crashes before it transfers the messages, messages are gone forever.
We may try to publish the message first, wait for a successful response from the broker, and commit changes to service A local database. This still won't guarantee the data consistency, as service A may crash before it has a chance to commit changes to its own database.

Let's assume that messages are published successfully first, and our application is not crashed before doing local database updates. The databse commit can be blocked if there are other concurrent database transactions acquiring locks on database objects we are trying to modify. Database transactions are normally isolated (transaction isolation), so updated data is only visible after the transaction is complete. Consumer services may try to fetch the new data before it is visible (messages are already sent to consumer services)
What can we do?
To avoid mentioned issues, we need to modify one of the two resources (data store, database) and drive the update of the second one based on that (we consisder the communication between two services in this case). We also need to do that in an eventually consistent manner. One service should act as a source of truth that allows "read your own writes" pattern. we then offer a reliable and eventually consistent data transfer across service boundaries.
We can think of a simple solution that does not involve message broker - performing synchronous calls for service communication using RESTful API.

Service A can make a HTTP request (POST, PUT) to external services and wait for responses right after the transaction is committed on its local database. However, this approach comes with downsides. Synchronous calls make services tightly coupled together, and all services must be available in order for API calls to be processed. This approach also does not scale well if the system is under high load.
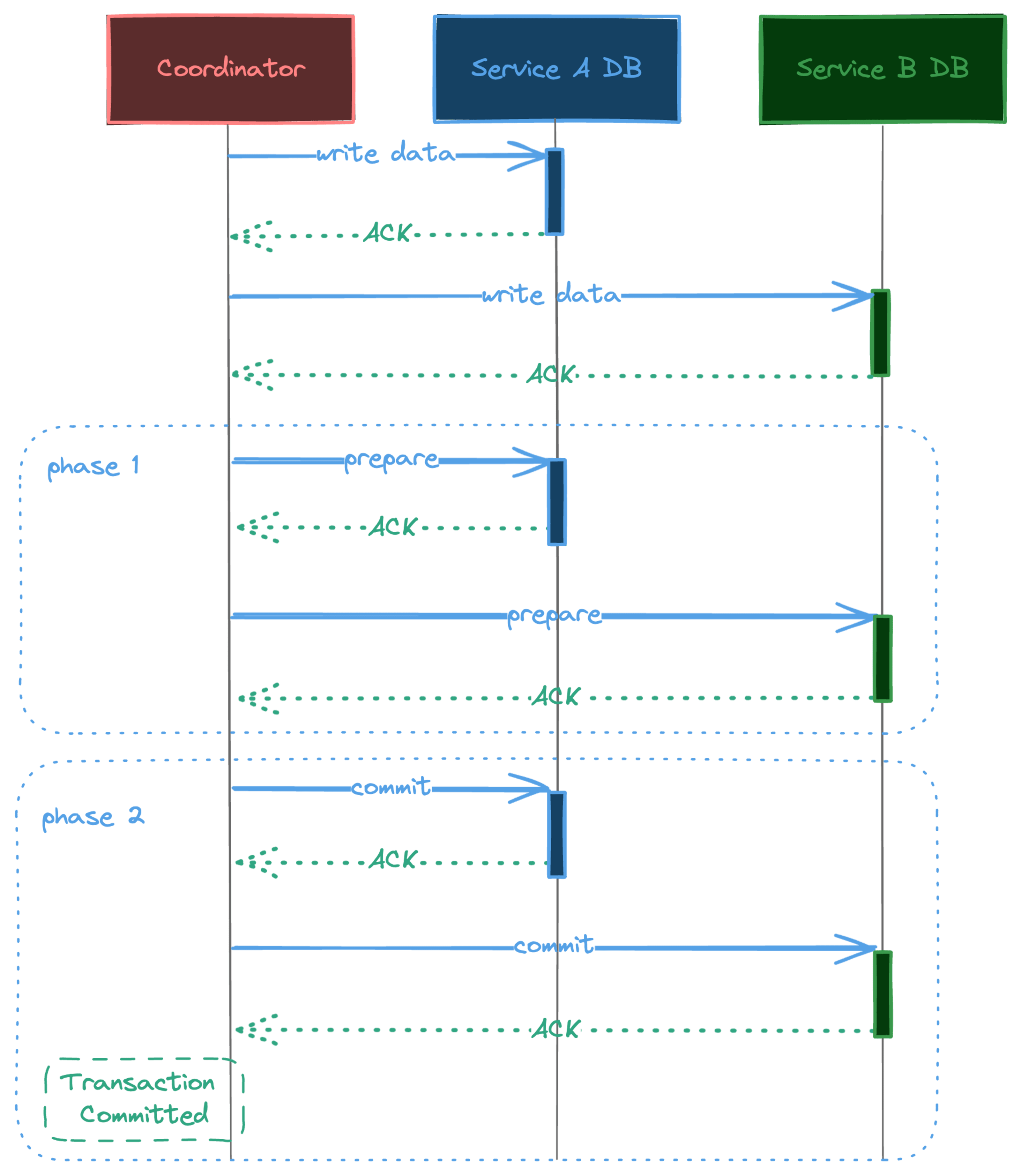
We can utilize distributed transaction like 2PC (Two-Phase Commit) to establish transaction management that spans across databases and message brokers. However, this method is not applicable for modern brokers such as Kafka, as it does not support distrubuted transactions. 2PC also suffers from performance overhead. The coordination process complexity increases when the number of participants in the transaction increases. 2PC depends on a coordinator to orchestrate the transaction, so we introduce a single point of failure in the system.
In the next section, we introduce Transactional Outbox, which is a simple method for letting services execute two actions in a safe and consistent manner.
Transactional Outbox
Recall that we have two actions that need to be processed atomically:
- Perform local database transaction in source service to accomplish business requirements (we can use ACID transaction in relational database for example)
- Perform external call to message broker or other services to propagate changes.
In the best-case scenario, we don't face issues if both actions succeed. However, problems arise when one action fails.
In previous examples, in memory messages cause lots of trouble when handling failures, so let's address that first.
We introduce a new database table to store all messages that will be delivered to external parties.
You can name it anything as you like, but let's call the table as outbox_event in the context of this writing.
Instead of publishing messages directly to message broker or other services, we first store them in outbox_event table.
Now, can can do two database operations: updating business logic and inserting message to outbox table in a single
local database transaction. If the transaction failed or it is rollbacked, no message is persisted in the outbox_event table.

The record in outbox_event table should contain necessary information to describe business needs and useful contextual information
to be used by consuming services. We will discuss implementation details for this table in the next section.
Below are some benefits regarding the outbox_event table:
- No need to introduce transactional context across service boundaries like 2PC.
- Guarantee read your own writes as we are writing to both business table and outbox table synchronously. Once the transaction was committed, subsequent query will access the latest business data.
- Act as a history table to monitor published events (note that we use messages and events interchangeably).
- Asynchronous eventually consistent when propagate changes to external services.
In the next step, we need to process records inside outbox_event table. There are several ways we can do:
- Introduce Event Publisher background asynchronous process that monitors
outbox_eventtable for new records. - Utilize CDC (Change Data Capture) and read the database transaction commit log.
Event Publisher
The idea is that we implement an asynchronous process to monitors the outbox_event table for new records.
If there are any new records, it fetches and distributes the messages to the message broker and mark the records as processed.
Event publisher should be implemented as a scheduled job and runs in scheduled intervals. If it fails to process
the record, that record can be retried in the next round.
Event Publisher can be called as Relay Publisher or Message Relay
Note that in the case that event publisher finished to publish an event to the message broker but fails to mark records as processed, the event will be sent to the broker more than one time. As such, it is important to deduplicate events. When using message broker, producers and consumers should be idempotent. An idempotent producer can help if the broker connection fails due to network issues, while an idempotent consumer helps to deduplicate events retried by the producer.
One of the main improvement of the transactional outbox is that events are stored in durable storage. If our service crashed before processing events, events are not lost. They will be processed once the service is recovered and event publisher kicks in.
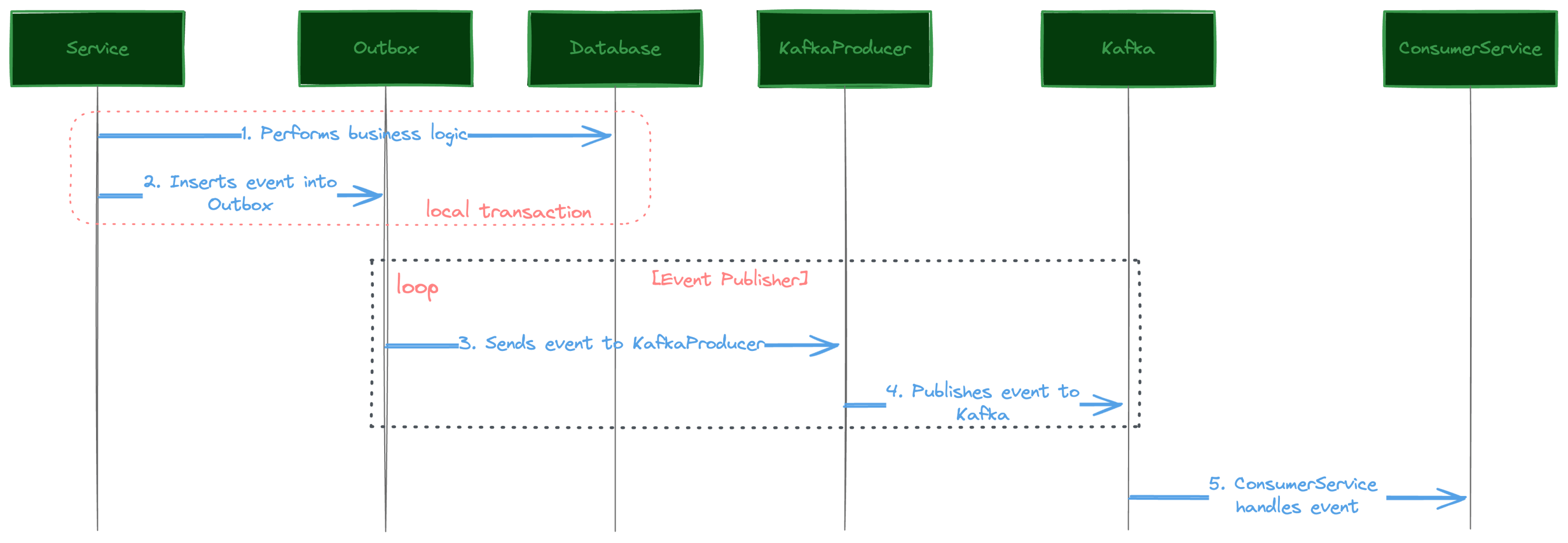
Event publisher is simple approach to implement, but it also comes with some drawbacks:
- Logic for transactional outbox should be impelemented as a standalone module and be reused across services.
- We need to maintain the scheduled process to monitor records in the
outbox_eventtable. Pullingoutbox_eventtable may put stress on your database. We can reduce that by decreasing scheduler frequency, but it will impact the latency of the message delivery. Another way is to use batch-processing when querying data fromoutbox_eventtable. However, if the request fails, none of the selected records will be mark as processed (delivered). - Limit support for NoSQL databases.
Implementing parallelism can accelerate the processing of outbox_event records. For example, multiple threads can
pick batch of records from outbox_event and send them concurrently to the message broker. However, to prevent threads
to select the same records multiple times, we need to block records when selecting. Some relational databases like
PostgreSQL support locking mechanism that we can utilize (SELECT ... FOR UPDATE SKIP LOCKED in PostgreSQL as an example).
We discussed one benefit of the outbox_event table, which is its ability to store event history. However, the outbox_event table will bloat
if we have lots of events. We can either delete records right after the events are published or adding another background
process to delete records from outbox_event table at scheduled intervals.
Transaction Commit Log
By employing a relational database for the outbox_event table, we can leverage the transaction commit log (or database log tailing) to track new records,
eliminating the need for a separate background process to monitor the table. Each operation in relational database like PostgreSQL
is recorded in write-ahead-log (WAL). It can be queried later for new records inserted into the outbox_event table. This is know as
CDC (Change Data Capture). Our transaction log processor reads transaction log entries, converts each entry to relevant event and
publishes to the message broker. The processor should exclude all operations except INSERT operations.
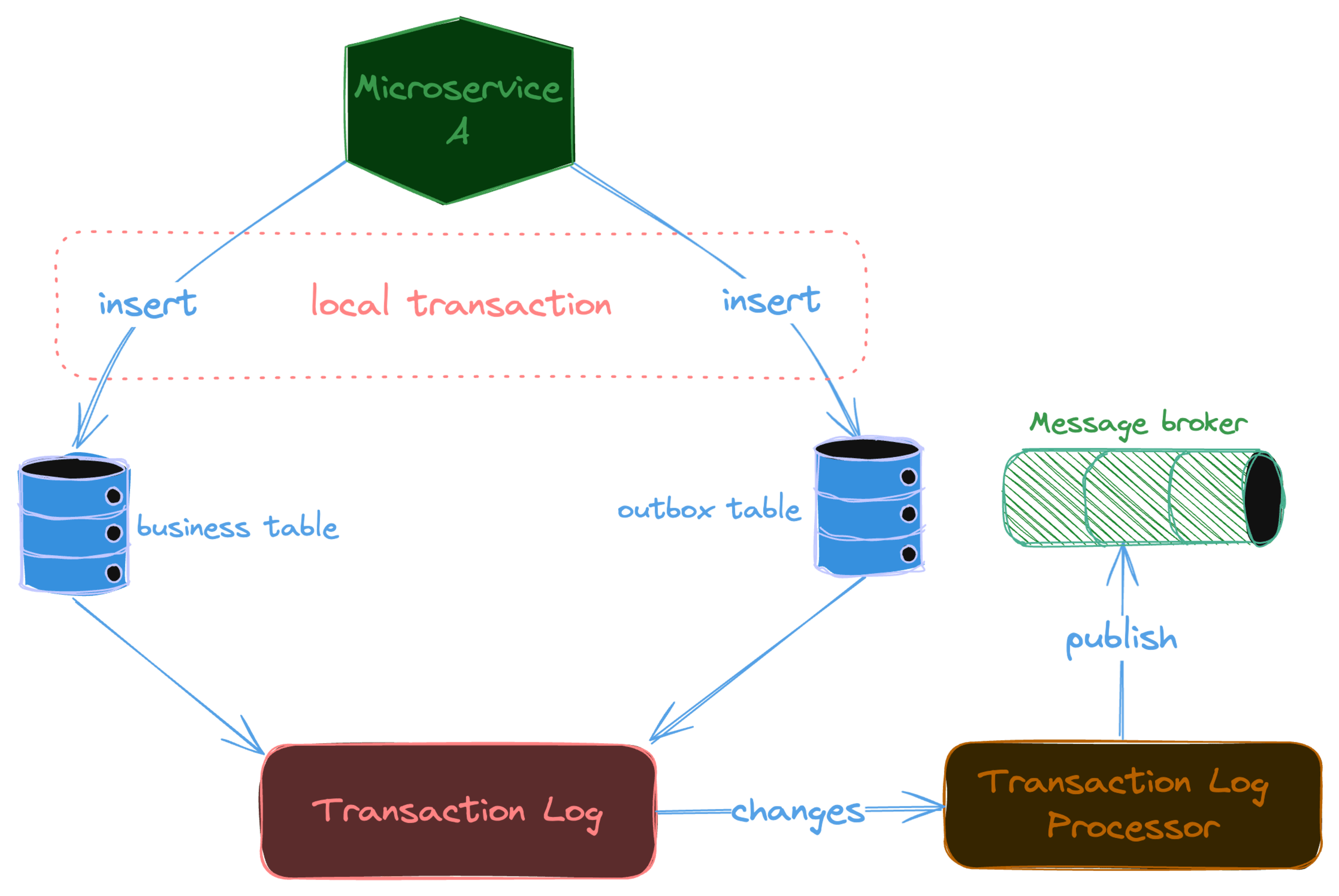
To use this method, your database must support CDC capabilities. It is also harder to impelement compared to Event Publisher approach. Let's discuss pros and cons using this method.
Pros
- Low latency and overhead when processing events.
Cons
- Requires CDC support.
- Transaction log may be truncated if our processor is too slow or not available, resulting in missing events.
- Tightly coupled with storage technology, implementation may be different per database engine.
We will concentrate on Event Publisher in the implementation section, as Transaction Commit Log is uncommon in real-world applications.
Transactional inbox
This article focuses on the publisher side using transactional outbox pattern. How about the consumer side of the process?
We can use transactional inbox pattern to reliably receive messages and process each message exactly once. We won't delve into the details of this pattern, but here are some general concepts:
- Messages sent to message broker is stored in a queue.
- Implement a background process to consume messages from queue and insert new records in
inbox_event. This process should use a unique identifier as the table primary key, so that each message is stored only once in the table (we can use idempotency key defined in the event for example). - A consumer reads records from
inbox_eventand process them. Similar to transactional outbox, updating business logic and updatinginbox_eventactions are wrapped into a single database transaction. If error happens during record processing, that record can be retried for several times as configured.
Using transactional outbox and transactional inbox patterns together guarantees the exactly once when processing with at least once delivery.
Implementation
Let's discuss a bit about how we can implement transactional outbox in our code. Before we begin, we assume that our application is using the following technologies:
- PostgreSQL: our main database where we define the
outbox_eventtable and other business tables. - Kafka: main message broker.
- Any back-end programming language of choice (Go, Java, Node.js, etc.)
First, we need to define the structure for outbox_event table. There is no concrete definition for table schema,
the structure could vary based on your application. However, we should specify the following columns:
| Column | Description |
|---|---|
| ID | the table primary key (can be UUID, auto-increment ID) |
| Idempotency Key | universal unique identifier for the event (UUID for example). This column can be used by consumers to deduplicate events |
| Key | the event key if specified by your application (type of byte array) |
| Payload | the content of the event, usually be a JSON-like object |
| Event Type | application-specific type of business event |
| Root Entity ID | type of the main entity to which a given event is related (order ID for example) |
| Root Entity Type | type of the main entity to which a given event is related (Order for example) |
| Published | a boolean value indicating that the record was processed and published to message broker |
| Published Time | the timestamp when the producer record was handled to the kafka producer |
| Acknowledgement Time | the timestamp when the event was processed (successful or failed) and acknowledged |
| Retry Count | failed events can be retried and the number of retries is recorded in this column |
| Other supplemental data | topic name, partition ID, created time, updated time, etc. |
Below is the SQL query to create above table, you can put this in the database migration scripts.
CREATE TABLE IF NOT EXISTS outbox_event (
id VARCHAR(255) NOT NULL,
idempotency_key VARCHAR(255) NULL,
key bytea NULL,
payload bytea NOT NULL,
event_type VARCHAR(255) NULL,
root_entity_id VARCHAR(255) NULL,
root_entity_type VARCHAR(255) NULL,
published boolean NULL,
published_time timestamp NULL,
ack_time timestamp NULL,
retry_count int4 NULL,
partition_id VARCHAR(255) NULL,
topic VARCHAR(255) NOT NULL,
created_time timestamp NULL,
updated_time timestamp NULL,
CONSTRAINT outbox_event_pkey PRIMARY KEY (id)
);
Transactional outbox logic can be implemented as a sub-module in your application code or as a separate reusable library. However, the general flow is illustrated in the below diagram.
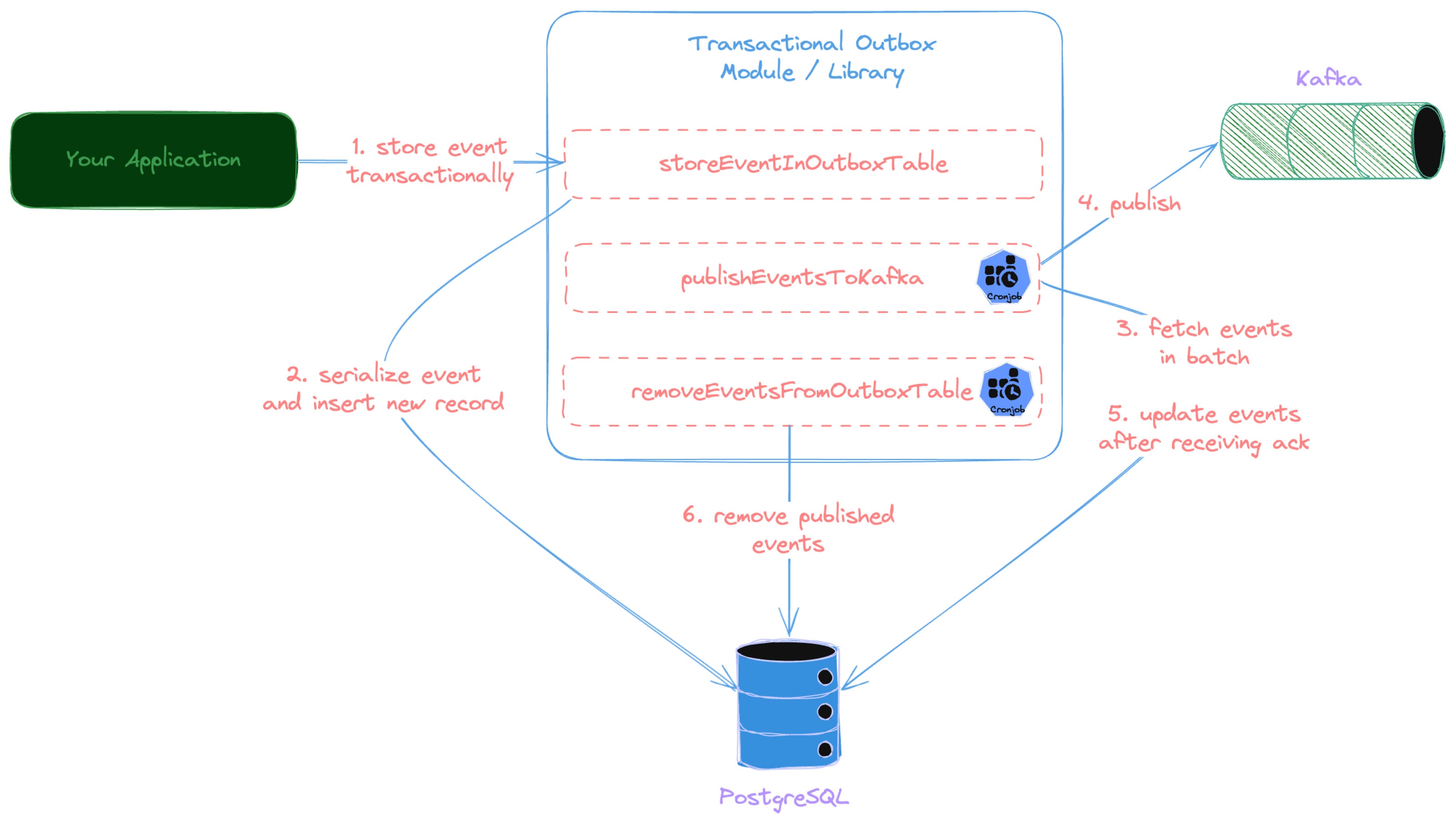
Let's discuss each step in detail:
Store event in outbox table (1, 2)
storeEventInOutboxTable is a helper method that takes the constructed event from your application, serializes it, and stores it
in the outbox_event table.
Why serialization?
Note that our key and payload columns have bytea type, so we need to convert data to bytes before storing.
Generally, key and payload are not simple primitive types such as string or number. In real-world application,
we may define our key and event schemas using tool like Avro, key and payload can be complex objects. That's
why we need explicit serialization.
Why transaction?
Storing an event in the outbox_event table is not an independent action; it is typically carried out alongside other business actions within your application.
Therefore, it is crucial that all these actions are performed atomically. Failing to do so can lead to data inconsistency issues.
What event properties should be provided by your application?
idempotency_key, key, payload, topic, event_type, root_entity_id, root_entity_type are application-specific properties,
so we need to provide them from application side.
We can initialize some other properties when performing storeEventInOutboxTable method such as setting published to false, setting
retry_count to 0, setting created_time.
Publish events to Kafka (3, 4, 5)
publishEventsToKafka is a scheduled job that do the following:
- Find unpublished events in
outbox_eventtable, query records in batch. The database query should order records bycreated_time.
-- Sample query with batch size of 100
SELECT * FROM outbox_event
WHERE published_time IS NULL
ORDER BY created_time ASC
LIMIT 100
-
Publish events concurrently to Kafka. For example, we can use
Promise.allin Node.js orCompletableFuturein Java. For each event, there are some smaller actions:- Retrieve event key, payload and Kafka topic from outbox record.
- Publish event to Kafka.
- Set
published_timeto current timestamp. - Set
publishedtotrue. - Set
ack_timeto current timestamp. - Set
partition_idfrom the Kafka publishing result.
If an error occurs during event publishing, the following steps are required:
- Set
publishedtofalse. - Increase
retry_countby1. - Set
ack_timeto current timestamp.
After all, we need to persist updated record in
outbox_eventtable.
Not that all above actions should be wrapped in a database transaction.
Purge published events (6)
The outbox_event table is bloat very quickly if your application publishes a lot of events. As a result, it is necessary to clean that
table up periodically. The removeEventsFromOutboxTable method is a scheduled job that scans the outbox_event table for successfully
published events and deletes them from the table. We can choose to delete all recent records or define a retention period (30 days for example)
and only delete records prior to that period. Retention period allows us to keep track of event history which is useful for debugging purposes.
Here is sample database query to delete all recent records in batch:
--Sample query with batch size of 100
DELETE FROM outbox_event WHERE id IN (
SELECT id FROM outbox_event oe
WHERE oe.published_time IS NOT NULL
AND oe.published = true
ORDER BY oe.published_time ASC
LIMIT 100
)
and delete records with retention period:
--Sample query with batch size of 100
DELETE FROM outbox_event WHERE id IN (
SELECT id FROM outbox_event oe
WHERE oe.published_time IS NOT NULL
AND oe.published_time <= :dateToPurge
AND oe.published = true
ORDER BY oe.published_time ASC
LIMIT 100
)
Concurrent Record Processing
Suppose your application is deployed across multiple instances, in which case you'll have multiple scheduled jobs
scanning the outbox_event table to process pending records.
To prevent a record is picked up multiple times by different jobs, we can:
Use FOR UPDATE SKIP LOCKED when querying unpublished events from table. The idea is that when retrieving
rows to lock, it skips over any rows that are already locked by other transactions in other processes. As a result,
we can safely allow multiple processes to concurrently process records from the outbox_event table.
Using SKIP LOCKED reduces lock contention and waiting time for locks to be released. That improves the overall throughput.
However, if some records take long time to process, those records may be skipped over repeatedly. The order in which
records are processed is not strictly guaranteed, so if your application requires strict ordering of events, this method
might not suitable.
SELECT * FROM outbox_event
WHERE published_time IS NULL
ORDER BY created_time ASC
LIMIT 100
FOR UPDATE SKIP LOCKED;
UPDATE outbox_event SET published = true ...
If event ordering is important in order to achieve business requirements, we can limit one scheduled job to access
outbox_event table at a time. We can do that by using distributed locks to manage scheduled jobs, allowing at most
once job to be executed at the same time. If a task is being executed on one node (process, thread), it acquires that lock
which prevents execution of the same tasks from another node. We can use Redis locks or library like ShedLock
for Java, Atomic Locks in Laravel framework, etc.
Recap
The transactional outbox pattern ensures reliable message delivery in distributed systems. It stores outgoing messages in the same database transaction as the business data change, ensuring atomicity. A separate process polls the outbox table, retrieves unprocessed events, and delivers them to the intended destination. This guarantees that events are not lost, even in the face of failures, and ensures eventual consistency in the system.
Transactional outbox is not on-size-fit-all solution, you need to analyze your application requirements before choosing it.
Everything in software architecture is a trade-off. -- The first law of software architecture (Mark Richards and Neal Ford).



")